The trie is helpful when processing multiple strings at once, but when we want to analyze
a single string, we need something different.
In this problem, we will use a new data structure to handle the problem of finding
long repeats in the genome. Recall from “Finding a Motif in DNA” that cataloguing these repeats
is a problem of the utmost interest to molecular biologists, as a natural correlation exists
between the frequency of a repeat and its influence on RNA transcription.
Our aim is therefore to identify long repeats that occur more than some predetermined number of times.
Problem
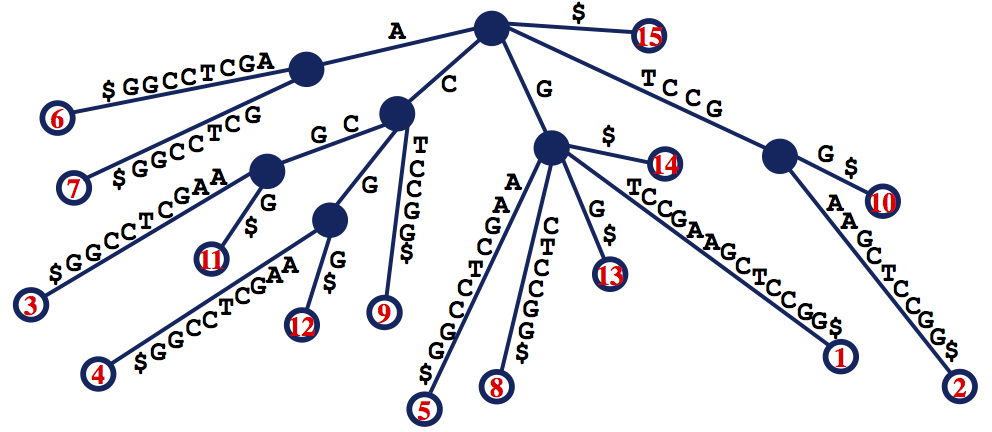
Figure 1. The suffix tree for s = GTCCGAAGCTCCGG. Note that the dollar sign has been appended to a substring of the tree to mark the end of s. Every path from the root to a leaf corresponds to a unique suffix of GTCCGAAGCTCCGG, and each leaf is labeled with the location in s of the suffix ending at that leaf.
Given: A DNA string$s$ (of length at most 20 kbp) with $ appended,
a positive integer $k$, and a list of edges defining the suffix tree of $s$.
Each edge is represented by four components:
the label of its parent node in $T(s)$;
the label of its child node in $T(s)$;
the location of the substring $t$ of $s^{*}$ assigned to the edge; and
the length of $t$.
Return: The longest substring of $s$ that occurs at least $k$ times in $s$. (If multiple solutions
exist, you may return any single solution.)